library(sf)
library(tmap)
library(rosm)
library(spdep)
library(ggplot2)
library(tidyr)
library(patchwork)Lab
Spatial autocorrelation and Exploratory Spatial Data Analysis Spatial autocorrelation has to do with the degree to which the similarity in values between observations in a dataset is related to the similarity in locations of such observations. Not completely unlike the traditional correlation between two variables -which informs us about how the values in one variable change as a function of those in the other- and analogous to its time-series counterpart -which relates the value of a variable at a given point in time with those in previous periods-, spatial autocorrelation relates the value of the variable of interest in a given location, with values of the same variable in surrounding locations.
A key idea in this context is that of spatial randomness: a situation in which the location of an observation gives no information whatsoever about its value. In other words, a variable is spatially random if it is distributed following no discernible pattern over space. Spatial autocorrelation can thus be formally defined as the “absence of spatial randomness”, which gives room for two main classes of autocorrelation, similar to the traditional case: positive spatial autocorrelation, when similar values tend to group together in similar locations; and negative spatial autocorrelation, in cases where similar values tend to be dispersed and further apart from each other.
In this session we will learn how to explore spatial autocorrelation in a given dataset, interrogating the data about its presence, nature, and strength. To do this, we will use a set of tools collectively known as Exploratory Spatial Data Analysis (ESDA), specifically designed for this purpose. The range of ESDA methods is very wide and spans from less sophisticated approaches like choropleths and general table querying, to more advanced and robust methodologies that include statistical inference and an explicit recognition of the geographical dimension of the data. The purpose of this session is to dip our toes into the latter group.
ESDA techniques are usually divided into two main groups: tools to analyze global, and local spatial autocorrelation. The former consider the overall trend that the location of values follows, and makes possible statements about the degree of clustering in the dataset. Do values generally follow a particular pattern in their geographical distribution? Are similar values closer to other similar values than we would expect from pure chance? These are some of the questions that tools for global spatial autocorrelation allow to answer. We will practice with global spatial autocorrelation by using Moran’s I statistic.
Tools for local spatial autocorrelation instead focus on spatial instability: the departure of parts of a map from the general trend. The idea here is that, even though there is a given trend for the data in terms of the nature and strength of spatial association, some particular areas can diverege quite substantially from the general pattern. Regardless of the overall degree of concentration in the values, we can observe pockets of unusually high (low) values close to other high (low) values, in what we will call hot(cold)spots. Additionally, it is also possible to observe some high (low) values surrounded by low (high) values, and we will name these “spatial outliers”. The main technique we will review in this session to explore local spatial autocorrelation is the Local Indicators of Spatial Association (LISA).
Data
For this session, we will use the results of the 2016 referendum vote to leave the EU, at the local authority level. In particular, we will focus on the spatial distribution of the vote to Leave, which ended up winning. From a technical point of view, you will be working with polygons which have a value (the percentage of the electorate that voted to Leave the EU) attached to them.
All the necessary data have been assembled for convenience in a single file that contains geographic information about each local authority in England, Wales and Scotland, as well as the vote attributes. The file is in the geospatial format GeoPackage, which presents several advantages over the more traditional shapefile (chief among them, the need of a single file instead of several). The file is available as a download from the course website.
# Read the file in
br <- read_sf("./data/UK-brexit/brexit.gpkg")Preparing the data
Let’s get a first view of the data:
base = osm.raster(br)
tm_shape(base) + tm_rgb() +
tm_shape(br) +
tm_borders(col = "white", lwd = 0.5) +
tm_fill(col = "coral1", alpha=0.5) +
tm_compass(position = c("left", "top")) +
tm_scale_bar(position = c("right", "bottom")) 
Spatial weights matrix
As discused before, a spatial weights matrix is the way geographical space is formally encoded into a numerical form so it is easy for a computer (or a statistical method) to understand. We have seen already many of the conceptual ways in which we can define a spatial weights matrix, such as contiguity, distance-based, or block.
For this example, we will show how to build a queen contiguity matrix, which considers two observations as neighbors if they share at least one point of their boundary. In other words, for a pair of local authorities in the dataset to be considered neighbours under this \(W\), they will need to be sharing border or, in other words, “touching” each other to some degree.
Technically speaking, we will approach building the contiguity matrix in the same way we did in the previous lab. We will begin with a dataframe and pass it on to the queen contiguity weights builder from the spdep package.
# list all adjacent polygons for each polygon
nb_q <- poly2nb(br, queen = TRUE) # Construct neighbours list from polygon listw_queen <- nb2listw(nb_q, style = "B") # Create a spatial weights matrix using queen contiguityError in nb2listw(nb_q, style = "B"): Empty neighbour sets foundYou will likely obtain an error message when running the cell above since the nb2listw() function doesn’t like when some polygons don’t have neighbours. These neighbourless polygons are islands. We can explicitly ask the function to still compute the spatial weights matrix even when some observations might not have neighbours. We do this by adding the zero.policy=TRUE argument:
w_queen <- nb2listw(nb_q, style = "B", zero.policy=TRUE) # Create a spatial weights matrix using queen contiguityHowever, observations with zero neighbours can can sometimes create issues in the analysis and distort the results. There are several solutions to this situation such as connecting the islands to other observations through a different criterion (e.g. nearest neighbor), and then combining both spatial weights matrices. For convenience, this time we will just remove them from the dataset because they are a small sample and their removal is likely not going to have a large impact in the calculations.
isolates <- which(w_queen$neighbours == "0")br <- br[-c(isolates),]Once we have the set of local authorities that are not an island, we need to re-calculate the weights matrix. We will create it so that it is row-standardised (so setting style to W:
# list all adjacent polygons for each polygon
nb_q <- poly2nb(br, queen = TRUE) # Construct neighbours list from
w_queen_std <- nb2listw(nb_q, style = "W") # Create a spatial weights matrix using queen contiguity and row-standardardised weightsSpatial lag
Once we have the data and the spatial weights matrix ready, we can start by computing the spatial lag of the percentage of votes that went to leave the EU. Remember the spatial lag is the product of the spatial weights matrix and a given variable and that, if \(W\) is row-standardized, the result amounts to the average value of the variable in the neighborhood of each observation.
We can calculate the spatial lag for the variable Pct_Leave (percentage that voted leave) and store it directly in the main table with the following line of code:
br$w_Pct_Leave <- lag.listw(w_queen_std, br$Pct_Leave)Let us have a quick look at the resulting variable, as compared to the original one:
head(br$Pct_Leave)[1] 69.57 65.48 66.19 61.73 56.18 57.42head(br$w_Pct_Leave)[1] 59.64000 60.52667 60.37667 60.48800 57.43000 51.26800The way to interpret the spatial lag (w_Pct_Leave) for the first observation is as follows: LAD with code E06000001 (Hartlepool), where 69,6% of the electorate voted to leave is surrounded by neighbouring local authorities where, on average, almost 60% of the electorate also voted to leave the EU. For the purpose of illustration, we can in fact check this is correct by querying the spatial weights matrix to find out Hartepool’s neighbors:
w_queen_std$neighbours[[1]][1] 4 46And then checking their values:
br$Pct_Leave[[4]][1] 61.73br$Pct_Leave[[46]][1] 57.55The average value, which we saw in the spatial lag is 59.64, can be verified as follows:
mean(c(br$Pct_Leave[[4]], br$Pct_Leave[[46]]))[1] 59.64For some of the techniques we will be seeing below, it makes more sense to operate with the standardised version of a variable, rather than with the raw one. Standardising means to subtract the average value to each observation of a variable and divide this by the standard deviation of the variable. This can be done easily with a bit of basic algebra:
br$Pct_Leave_std <- (br$Pct_Leave - mean(br$Pct_Leave))/sd(br$Pct_Leave)Finally, to be able to explore the spatial patterns of the standardised values, also called sometimes \(z\) values, we need to create its spatial lag:
br$w_Pct_Leave_std <- lag.listw(w_queen_std, br$Pct_Leave_std)Global spatial autocorrelation
Global spatial autocorrelation relates to the overall geographical pattern present in the data. Statistics designed to measure this trend thus characterize a map in terms of its degree of clustering and summarise it. This summary can be visual or numerical. In this section, we will walk through an example of each of them: the Moran Plot, and Moran’s I statistic of spatial autocorrelation.
Moran Plot
The moran plot is a way of visualising a spatial dataset to explore the nature and strength of spatial autocorrelation. It is essentially a traditional scatter plot in which the variable of interest is displayed against its spatial lag. In order to be able to interpret values as above or below the mean, and their quantities in terms of standard deviations, the variable of interest is usually standardised by substracting its mean and dividing it by its standard deviation.
As we saw in the previous lab, creating a Moran Plot is very similar to creating any other scatter plot in R, provided we have standardised the variable and calculated its spatial lag beforehand:
# Create a standardized Moran plot using ggplot2
moran_plot_z <- ggplot(br, aes(x=Pct_Leave_std, y=w_Pct_Leave_std)) +
geom_point() +
geom_smooth(method=lm) +
geom_hline(aes(yintercept = 0)) +
geom_vline(aes(xintercept = 0)) +
labs(title="Standardised Moran plot", x="% Leave z-score", y = "Lagged % leave")
# Apply a minimal theme to the standardized Moran plot
moran_plot_z + theme_minimal() 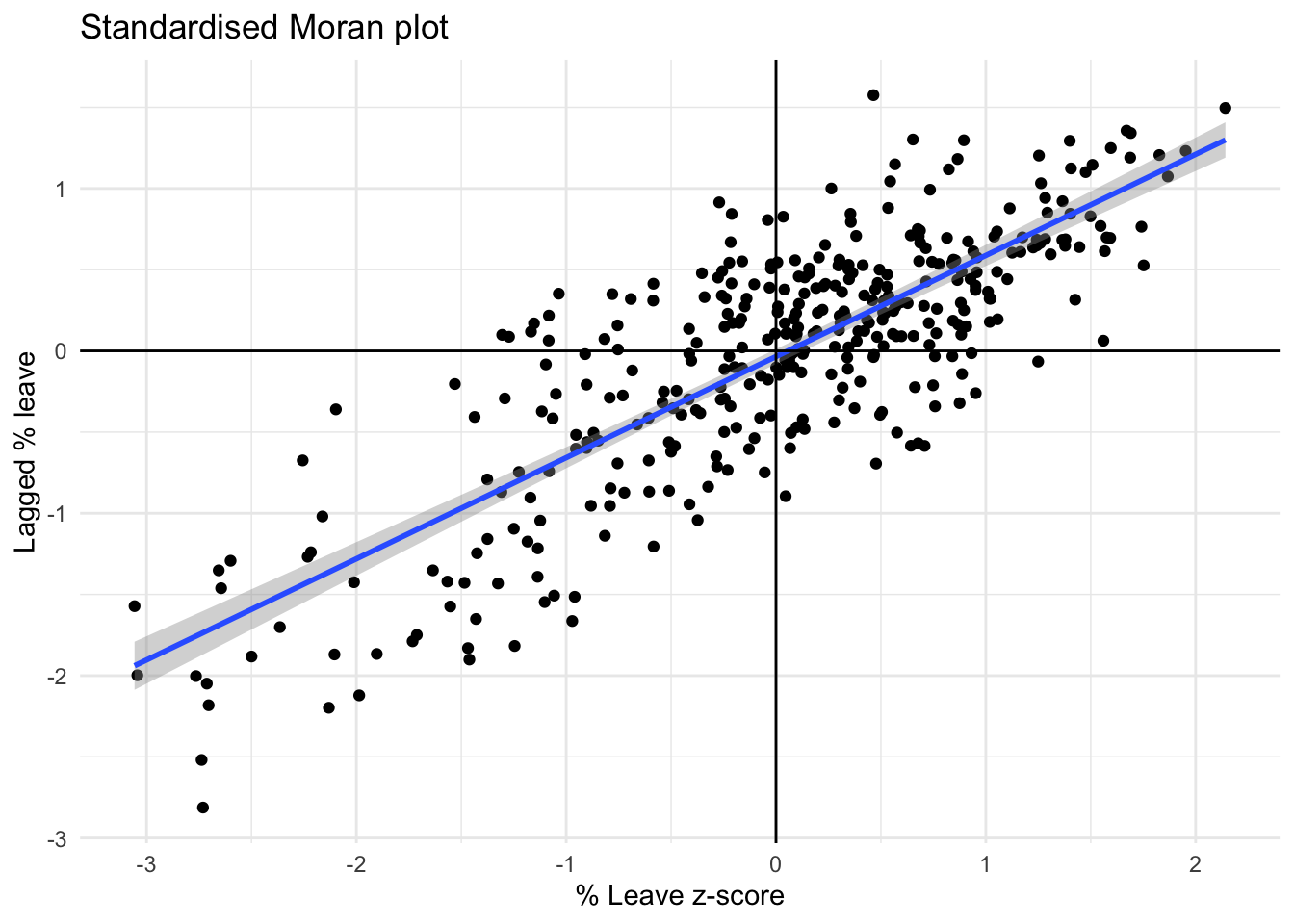
The figure above displays the relationship between the standardised percentage which voted to Leave the EU (Pct_Leave_std) and its spatial lag. Since the \(W\) that was used is row-standardised, it can be interpreted as the average percentage which voted to Leave in the surrounding areas of a given Local Authority. In order to guide the interpretation of the plot, a linear fit is also included. This line represents the best linear fit to the scatter plot or, in other words, the best way to represent the relationship between the two variables as a straight line.
The plot displays a positive relationship between both variables. This is associated with the presence of positive spatial autocorrelation: similar values tend to be located close to each other. This means that the overall trend is for high values to be close to other high values, and for low values to be surrounded by other low values. This, however, does not mean that this is the only situation in the dataset: there can of course be particular cases where high values are surrounded by low ones, and viceversa. But if we had to summarise the main pattern of the data in terms of how clustered similar values are, the best way would be to say that they are positively correlated and, hence, clustered over space.
In the context of the example, this can be interpreted along the lines of: local authorities display positive spatial autocorrelation in the way they voted in the EU referendum. This means that local authorities with high percentage of Leave voters tend to be located nearby other local authorities where a significant share of the electorate also voted to Leave, and viceversa.
Moran’s I
The Moran Plot is an excellent tool to explore the data and get a good sense of how much values are clustered over space. However, because it is a graphical device, it is sometimes hard to condense its insights into a more concise way. For these cases, a good approach is to come up with a statistical measure that summarises the figure. This is exactly what Moran’s I is meant to do.
Very much in the same way the mean summarises a distribution of values in a non-spatial setting, so does Moran’s I for a spatial dataset. Continuing the comparison, we can think of the mean as a single numerical value summarising a histogram or a kernel density plot. Similarly, Moran’s I captures much of the essence of the Moran Plot. In fact, there is a close connection between the two: the value of Moran’s I corresponds with the slope of the linear fit overlayed on top of the Moran Plot for the standardised variable and its lagged counterpart. Hence Morans’I takes values between -1 and 1, where a value of 0 would correspond to a random allocation of values of a variable across the possible locations. A value of 1 would correspond to a situation where the values of the variable of interest are optimally allocated in the map so that two neighbouring spatial units have as similar values as possible. Conversely, if Moran’s I is -1, this would correspond to a situation where neighbouring spatial units have as different values as possible.
In order to calculate Moran’s I in our dataset, we can call the moran.mc function in R:
moran.mc(br$Pct_Leave, w_queen_std, nsim=1000, alternative="greater")
Monte-Carlo simulation of Moran I
data: br$Pct_Leave
weights: w_queen_std
number of simulations + 1: 1001
statistic = 0.62286, observed rank = 1001, p-value = 0.000999
alternative hypothesis: greaterNote how we do not need to use the standardised version in this context as, behind the scenes, the formula for Moran’s I is already applying some standardisation to the input data.
The fucntion moran.mc() creates an object that contains much more information than the actual statistic. But we are interested in the statistic, which is the value of Moran’s I, in this case 0.62286; and the p-value. The p-value relates to statistical inference: if we considered the same variable but shuffled its locations randomly nsim=1000 times, how many times out of 1000 would we obtain a map with as clustered spatial patters as our observations? Or in other words, given a random spatial allocation of the data, what would be the probability of obtaining a value of Moran’s I higher than the one observed in the original spatial arrangement? This probability is the p-value. The specific details of the mechanism to calculate it are beyond the scope of the session, but it is important to know that if the p-value associated with the Moran’s I of a map is small enough (typically, anything smaller than 0.05 or 0.1 is considered small), then we can reject the hypothesis that the spatial patterns in the map arise by random chance. Furthermore, if we want to know the probability of obtaining a Moran’s I higher than the one observed given a random spatial allocation of the data, we need to set alternative to greater. If we wanted to know the probability of obtaining a Moran’s I lower than the one observed given a random spatial allocation of the data, we would need to set alternative to less. These two p-values, should add up to one. Finally, if we wanted to know the probability of obtaining a Moran’s I with an absolute value as high as the one observed given a random spatial allocation of the data, we would need to set alternative to two.sided.
In our case, the p-value is 0.000999. Since it is below 0.1, we can say that the observed spatial patters are statistically significant. What that p-value of 0.000999 means is that, if we generated a large number of maps with the same values but randomly allocated over space, and calculated the Moran’s I statistic for each of those maps, only 0.0999% of them would display a larger (absolute) value of Moran’s I than the one we obtain from the real data, and the other random maps would receive a smaller (absolute) value of Moran’s I. Therefore, we conclude that the particular spatial arrangement of values for the Leave votes is more spatially concentrated than a random spatial arrangement (hence Moran’s I > 0), and that it is highly unlikely that the observed spatial pattern would arise by chance (only about 0.0999% of random permutations of the data would give rise to spatial arrangements as concentrated as the observed).
Therefore, as a first step in Exploratory Spatial Data Analysis, the computation of the global autocorrelation can help us reveal whether the observations are positively correlated over space. In terms of our initial goal to find spatial structure in the attitude towards Brexit, we find that this is the case as Moran’s I is 0.62286 with a p-value < 0.05. If the vote had no spatial structure, it should not show a pattern over space and Morans’I would be closer to 0.
Local spatial autocorrelation
Moran’s I is a good tool to summarise a dataset into a single value that informs about its degree of clustering. However, it is not an appropriate measure to identify areas within the map where specific values are located. In other words, Moran’s I can tell us if values are clustered overall, but it will not inform us about where the clusters are. For that purpose, we need to use a local measure of spatial autocorrelation. Instead of operating on the overall dataset as global measures do, local measures consider each single observation in a dataset and operate on them. Because of that, they are not good a summarising a map, but they allow us to obtain further insights.
We will consider Local Indicators of Spatial Association (LISAs), a local counter-part of global measures like Moran’s I. Essentially, this method consists in classifying the observations in a dataset into four groups derived from the Moran Plot: high values surrounded by high values (HH), low values nearby other low values (LL), high values among low values (HL), and low values among high values (LH). Each of these groups are typically called “quadrants”. An illustration of where each of these groups fall into the Moran Plot can be seen below:
# Create a standardized Moran plot using ggplot2
moran_plot_z <- ggplot(br, aes(x=Pct_Leave_std, y=w_Pct_Leave_std)) +
geom_point() +
geom_smooth(method=lm) +
geom_hline(aes(yintercept = 0)) +
geom_vline(aes(xintercept = 0)) +
labs(title="Standardised Moran plot", x="% Leave z-score", y = "Lagged % leave") +
geom_label(aes(x=2.0, y=0.5, label="HH")) +
geom_label(aes(x=1.5, y=-1.5, label="HL")) +
geom_label(aes(x=-2, y=1.0, label="LH")) +
geom_label(aes(x=-1.5, y=-2.5, label="LL"))
# Apply a minimal theme to the standardized Moran plot
moran_plot_z + theme_minimal() 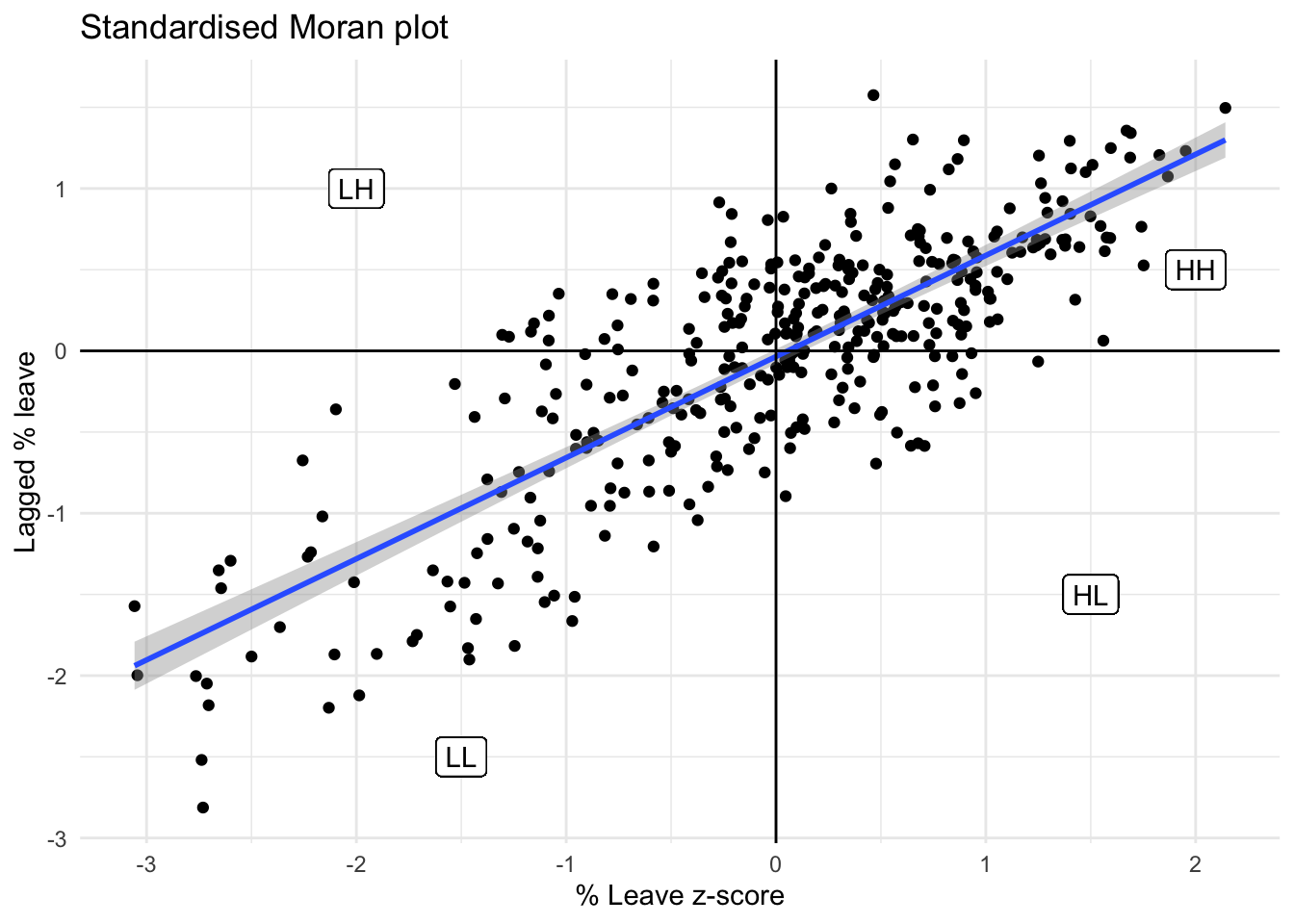
So far we have classified each observation in the dataset depending on its value and that of its neighbors. This is only half way into identifying areas of unusual concentration of values. To know whether each of the locations is a statistically significant cluster of a given kind, we again need to compare it with what we would expect if the data were allocated in a completely random way. After all, by definition, every observation will be of one kind or another based on the comparison above. However, what we are interested in is whether the strength with which the values are concentrated is unusually high.
This is exactly what LISAs are designed to do. As before, a more detailed description of their statistical underpinnings is beyond the scope in this context, but we will try to shed some light into the intuition of how they go about it. The core idea is to identify cases in which the comparison between the value of an observation and the average of its neighbors is either more similar (HH, LL) or dissimilar (HL, LH) than we would expect from pure chance. The mechanism to do this is similar to the one in the global Moran’s I, but applied to each observation, resulting then in as many statistics as original observations.
LISAs are widely used in many fields to identify clusters of values in space. They are a very useful tool that can quickly return areas in which values are concentrated and provide suggestive evidence about the processes that might be at work. For that, they have a prime place in the exploratory toolbox. Examples of contexts where LISAs can be useful include: identification of spatial clusters of poverty in regions, detection of ethnic enclaves, delineation of areas of particularly high/low activity of any phenomenon, etc.
In R we can calculate LISAs in a very streamlined way thanks to the localmoran_perm() function in the spdep package. We just need to input the variable of interest, the spatial weights, the number of simulations so that the function knows how many times to shuffle the data in order to compute the p-values. Furthermore, we include another argument, alternative="two.sided" which is also related to how the p-value is computed. Once again, understanding this bit is beyond the scope of this lecture. If you want to learn more about it, we recommend this reading (Sauer et al. 2022) by Sauer et al., although it is quite advanced! Below is the outcome of the local_perm function:
lisa_perm <- localmoran_perm(br$Pct_Leave, w_queen_std, nsim=1000, alternative="two.sided")
head(lisa_perm) Ii E.Ii Var.Ii Z.Ii Pr(z != E(Ii))
1 0.96481855 0.033662931 1.23818791 0.8368141 0.4026971
2 0.82335963 0.025134363 0.47156726 1.1623948 0.2450751
3 0.85318791 -0.021592764 0.51690982 1.2167232 0.2237096
4 0.56806645 0.003877416 0.13441570 1.5388619 0.1238380
5 0.11370566 -0.002057723 0.02051168 0.8082964 0.4189200
6 -0.07610997 0.005520772 0.03268878 -0.4514965 0.6516317
Pr(z != E(Ii)) Sim Pr(folded) Sim Skewness Kurtosis
1 0.3816184 0.19080919 -0.4012573 0.34355184
2 0.2397602 0.11988012 -0.2709340 -0.15456751
3 0.2137862 0.10689311 -0.4652117 0.53011360
4 0.0999001 0.04995005 -0.2850833 -0.04090148
5 0.4435564 0.22177822 -0.2837252 0.01082380
6 0.6293706 0.31468531 -0.3143774 0.01704071Because of their very nature, looking at the numerical result of LISAs is not always the most useful way to exploit all the information they can provide. Remember that we are calculating a statistic for every single observation in the data so, if we have many of them, it will be difficult to extract any meaningful pattern. Instead, typically a cluster map is created to reflect the significant observations (those that are highly unlikely to have happened by pure chance), which are plotted with a specific color depending on their quadrant category.
All of the needed pieces are contained inside the LISA object called lisa_perm that we have created above. But to make the creation of the cluster map more straightforward, it is convenient to pull them out and insert them in the main data table, br, in a new column called quadrant. To do this, we use the hotspot function to identify the observations with a siginificant value of the Local Moran’s I, setting the significance cutoff to 0.1. Note that we need to tell the function, what column of the lisa_perm object to look at for p-values smaller than 0.1. In our case, the p-values for the Local Moran’s I are stored in the column named "Pr(z != E(Ii)) Sim".
quadrants <- hotspot(lisa_perm, Prname="Pr(z != E(Ii)) Sim", cutoff=0.1)
quadrants [1] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[8] <NA> <NA> <NA> <NA> High-High High-High <NA>
[15] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[22] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[29] <NA> <NA> <NA> <NA> High-High <NA> <NA>
[36] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[43] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[50] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[57] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[64] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[71] High-High <NA> <NA> <NA> <NA> <NA> <NA>
[78] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[85] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[92] <NA> <NA> <NA> <NA> <NA> High-High <NA>
[99] High-High <NA> <NA> <NA> <NA> <NA> <NA>
[106] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[113] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[120] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[127] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[134] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[141] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[148] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[155] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[162] <NA> High-High High-High <NA> High-High High-High <NA>
[169] High-High <NA> <NA> <NA> High-High High-High <NA>
[176] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[183] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[190] <NA> <NA> High-High <NA> <NA> High-High <NA>
[197] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[204] <NA> <NA> <NA> <NA> <NA> <NA> High-High
[211] <NA> High-High High-High <NA> <NA> <NA> <NA>
[218] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[225] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[232] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[239] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[246] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[253] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[260] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[267] <NA> <NA> <NA> <NA> <NA> High-High High-High
[274] <NA> <NA> <NA> <NA> <NA> Low-High <NA>
[281] <NA> <NA> <NA> <NA> High-High <NA> <NA>
[288] <NA> <NA> <NA> <NA> Low-Low <NA> Low-Low
[295] <NA> Low-Low Low-Low Low-Low <NA> <NA> <NA>
[302] <NA> Low-Low <NA> Low-Low <NA> <NA> <NA>
[309] <NA> Low-Low Low-Low Low-Low Low-Low <NA> Low-Low
[316] Low-Low <NA> <NA> Low-Low <NA> Low-Low Low-Low
[323] Low-Low Low-Low <NA> <NA> Low-Low Low-Low Low-Low
[330] <NA> <NA> <NA> <NA> Low-Low <NA> Low-Low
[337] Low-Low Low-Low <NA> Low-Low Low-Low <NA> <NA>
[344] Low-Low Low-Low Low-Low Low-Low Low-Low <NA> <NA>
[351] Low-Low Low-Low Low-Low <NA> <NA> <NA> <NA>
[358] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[365] <NA> <NA> <NA> <NA> <NA> <NA> <NA>
[372] <NA> <NA> <NA>
Levels: Low-Low Low-High High-HighThen, we stor these results in a new column of br as characters, and replacing the NA values by "Not significant":
br$quadrant <- as.character(quadrants) %>% replace_na("Not significant")Let’s check that the new column was added by inspecting the first few lines of br:
head(br)Simple feature collection with 6 features and 8 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -2.832457 ymin: 53.30502 xmax: -0.7884185 ymax: 54.72716
Geodetic CRS: WGS 84
# A tibble: 6 × 9
objectid lad16cd lad16nm Pct_Leave geom w_Pct_Leave
<dbl> <chr> <chr> <dbl> <MULTIPOLYGON [°]> <dbl>
1 1 E06000001 Hartlepool 69.6 (((-1.270237 54.72716, -… 59.6
2 2 E06000002 Middlesbro… 65.5 (((-1.230014 54.5841, -1… 60.5
3 3 E06000003 Redcar and… 66.2 (((-1.137166 54.64693, -… 60.4
4 4 E06000004 Stockton-o… 61.7 (((-1.317743 54.64524, -… 60.5
5 5 E06000005 Darlington 56.2 (((-1.637991 54.61719, -… 57.4
6 6 E06000006 Halton 57.4 (((-2.626836 53.35462, -… 51.3
# ℹ 3 more variables: Pct_Leave_std <dbl>, w_Pct_Leave_std <dbl>,
# quadrant <chr>And how many different types of clusters do we have that are significant?
unique(br$quadrant)[1] "Not significant" "High-High" "Low-High" "Low-Low" Just three: High-High, Low-High and Low-Low. No significant High-Low cluters were detected. We can now plot the map of percentage of people that voted leave in each Local Authority Districts, and next to it, the cluster map from the LISA analysis:
map_pct <- tmap::tm_shape(br) +
tmap::tm_fill(col = "Pct_Leave", palette = viridisLite::viridis(6), title="% Leave voters") +
tm_borders(col = "black", lwd = 0.3)+
labs(title = "% Leave voters")+
tm_compass(position = c(0.01, 0.03)) +
tm_scale_bar(position = c(0.6, 0.03)) +
tm_layout(legend.text.size = 0.5, inner.margins = c(0.1, 0.1, 0.02, 0.05), legend.position = c(0.65,0.76), legend.width=0.5, bg.color="aliceblue")
borders <- tm_shape(br) +
tm_fill() +
tm_borders(col = "black", lwd = 0.3)
hh <- br %>% dplyr::filter(quadrant == "High-High")
hh_map <- tm_shape(hh) +
tm_fill(col = "royalblue2", alpha=0.8)
ll <- br %>% dplyr::filter(quadrant == "Low-Low")
ll_map <- tm_shape(ll) +
tm_fill(col = "red2", alpha=0.8)
lh <- br %>% dplyr::filter(quadrant == "Low-High")
lh_map <- tm_shape(lh) +
tm_fill(col = "gold", alpha=0.8)
ns <- br %>% dplyr::filter(quadrant == "Not significant")
ns_map <- tm_shape(ns) +
tm_fill(col = "lightgrey", alpha=0.8)
# Combine all the maps, add compass, scale bar, and legend
final_map_cluster <- borders +
hh_map + ll_map + lh_map + ns_map +
tm_compass(position = c(0.01, 0.03)) +
tm_scale_bar(position = c(0.6, 0.03)) +
tm_add_legend(type = "fill", col = c("royalblue2", "red2", "darkgreen", "gold", "lightgrey"),
labels = c("High-High", "Low-Low", "High-Low", "Low-High", "Not significant"), title = "LISA cluster") +
tm_layout(legend.text.size = 0.5, inner.margins = c(0.1, 0.1, 0.02, 0.05), legend.position = c(0.65,0.75), legend.width=0.5, bg.color="aliceblue")
tmap_arrange(map_pct, final_map_cluster)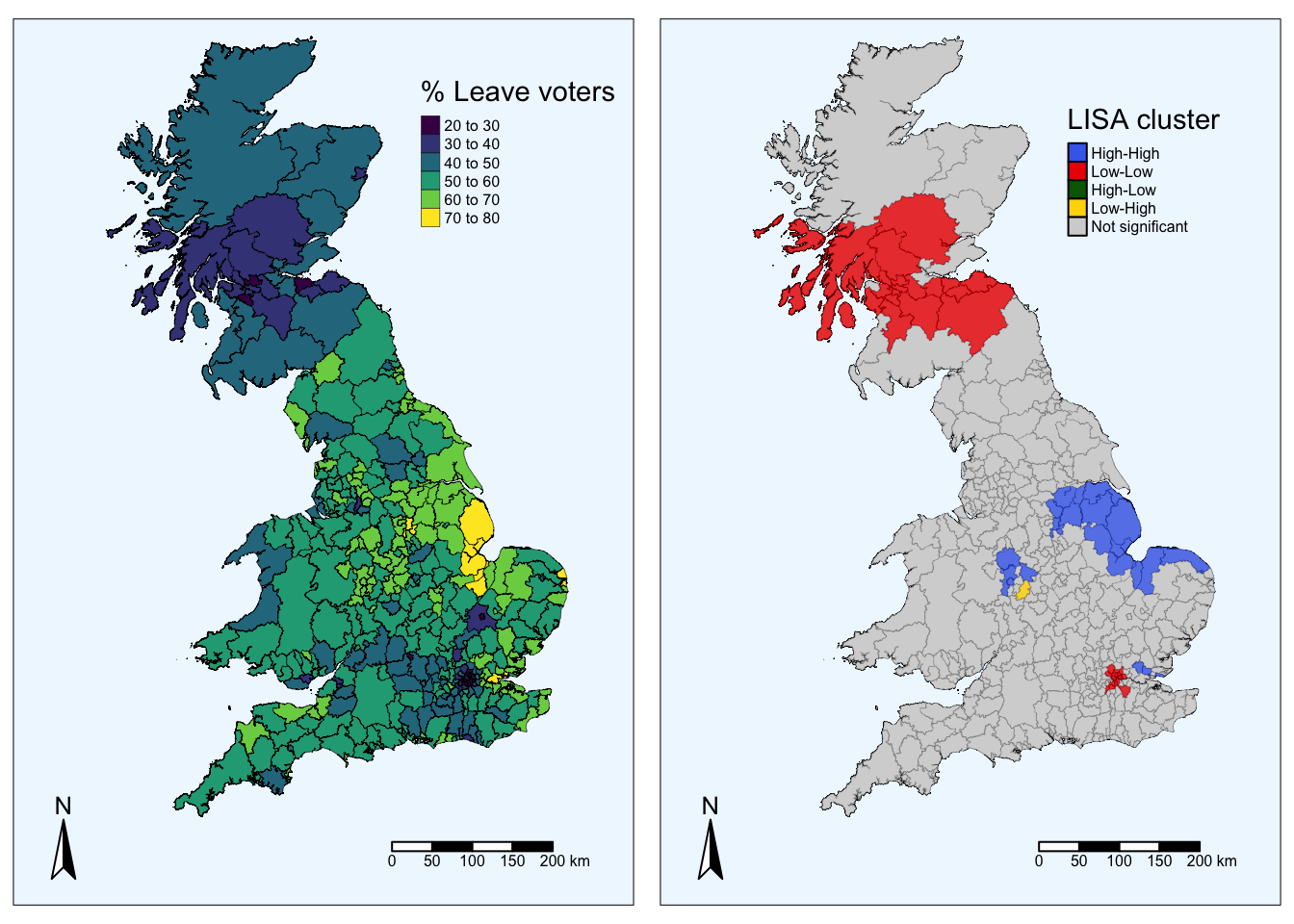
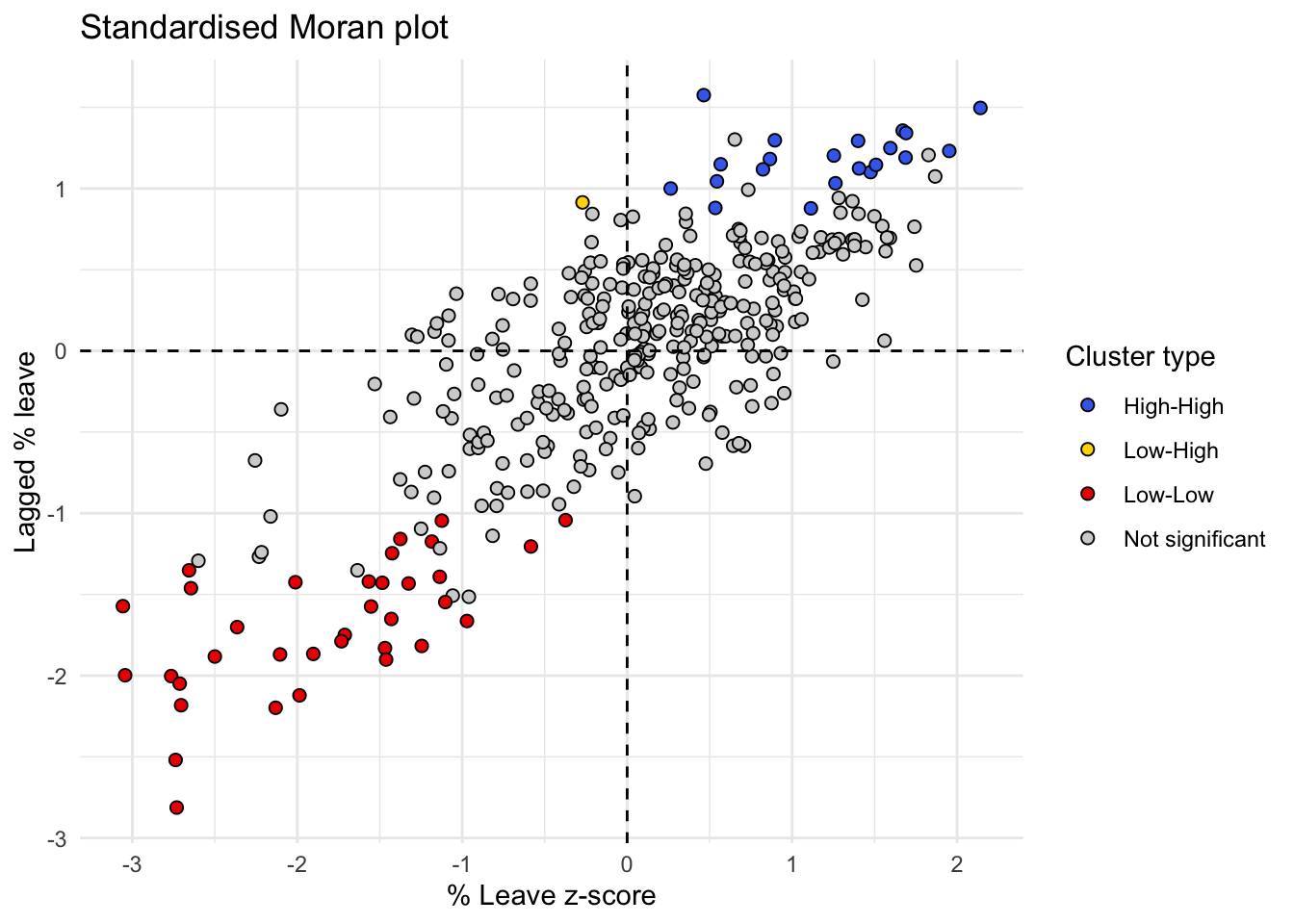
The map above on the right displays the LISA results of the Brexit vote. In blue, we find those local authorities with an unusual high concentration of Leave voters surrounded also by other local authorities with high levels of Leave vote. This corresponds to areas in the East of England, East London and some parts of the Midlands. In red, we find areas with low support for leaving the EU, surrounded by other areas that think alike. The first type of spatial outliers is highlighted in yellow, these are areas with low support for the Leave vote but which are surrounded by areas with high support. We do not find any statistically significant cases of areas with high support for leaving the EU surrounded by areas with low support.
Note
Are you able to see the connection between the choropleth map on the left and the LISA cluster map?
Finally, the results from the LISA statistics can be connected to the Moran plot to visualise where in the scatter plot polygon from different clusters fall:
color_values <- c(`High-High` = "royalblue2",
`Low-Low` = "red2",
`High-Low` = "darkgreen",
`Low-High` = "gold",
`Not significant` = "lightgrey")
moranLISA <- ggplot(br, aes(x=Pct_Leave_std,
y=w_Pct_Leave_std,
fill = quadrant)) +
geom_point(color = "black", shape = 21, size = 2) +
theme_minimal() +
geom_hline(yintercept = 0, linetype = "dashed") +
geom_vline(xintercept = 0, linetype = "dashed") +
scale_fill_manual(values=color_values) +
labs(title="Standardised Moran plot",
x="% Leave z-score",
y = "Lagged % leave",
fill = "Cluster type")
moranLISA